Massive HPC and AI chips call for parallelized, hierarchical, and distributed timing analysis.

Contemporary AI, high-performance computing (HPC), mobile, and automotive designs continue to grow in size and complexity, putting a strain on the high-capacity compute required for static timing analysis (STA) workloads. Designs continue to grow at an unprecedented rate in size and complexity, outpacing the capacity of existing high-performance compute servers. A modern STA solution that can handle today’s massive designs must address capacity and runtime requirements for billions of instances. Fast, powerful, and accurate STA requires three key innovative capabilities: efficient multi-core scaling in a single machine, hierarchical STA, and distributed STA.
Multi-core scaling in a single machine is a natural fit for today’s processors with a large number of CPU cores. For years, traditional STA workloads have used 8 CPU cores or 16 CPU cores, but modern private and public compute farms have machines with large numbers of CPU cores. For example, the latest HPC instances in public cloud platforms offer 96 CPU cores. Significant speedup in performance is achievable for multi-core applications that run the threads in parallel across multiple CPU cores. Using the same memory footprint inside the machine, timing analysis runtime should decrease as the number of threads increases and more cores are engaged in running the analysis.
Parallelism is one way to accelerate STA; hierarchical timing analysis is another. STA has traditionally been run on full flat netlists, which require large amounts of memory and run inefficiently for large designs. This issue can be solved by analyzing the design hierarchically so that each individual run analyzes only a portion of the whole design. For maximum user flexibility, both top-down and bottom-up hierarchical STA must be supported. All timing analysis must be performed in the context of the top-level design to ensure signoff-quality accuracy.
Distributed STA is another approach with a highly scalable capability that partitions the design across multiple servers and runs timing analysis in parallel. This use of distributed and reusable hardware resources reduces runtime, memory usage, and cost. Typically, a manager process partitions the design, starts up distributed client processes, and merges the timing results. Each client process reads in its design partition, performs timing and noise analysis, and sends the results back to the manager process. As with multiple cores, runtime should scale down as the number of servers and work processes grows.
All three of these advanced STA capabilities are available today in Synopsys PrimeTime, a trusted signoff solution for timing, signal integrity, and multiphysics-aware analysis. Synopsys PrimeTime has the capacity to handle the largest and most complex chips, with plenty of headroom to scale as designs grow to 10 billion instances over the next few years. This distinction is enabled by innovative technologies such as multi-core scaling, HyperScale hierarchical analysis, and HyperGrid distributed analysis.
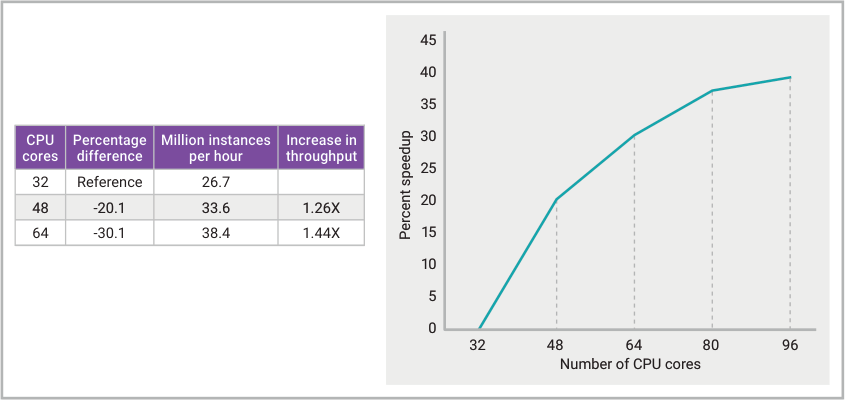
Synopsys PrimeTime has been enhanced with multi-core scaling capabilities to enable efficient usage when using more cores. All the steps in the PrimeTime analysis flow have been optimized for high multi-core scalability. A great benefit of this technology is that using the same machine memory, Synopsys PrimeTime can take advantage of the idle cores on the machine to provide faster runtime. At a recent Synopsys Users Group (SNUG) event, a team from NVIDIA reported similar results, with a better than 1.4X speedup from 32 to 64 cores when running STA on a 1 billion instance design. These results are shown in the graph below.
HyperScale technology in Synopsys PrimeTime supports both top-down and bottom-up hierarchical timing analysis to enable fast STA signoff with less powerful compute servers. On designs with hundreds of millions or billions of instances, the result is up to 10X faster performance and 10X less memory usage as compared to traditional flat STA. Hyperscale technology is a great fit for HPC, data center, and AI designs. Typically, these designs have many multiply instantiated repetitive blocks. PrimeTime HyperScale Multiply Instantiated Module (MIM) technology is intended for such designs to achieve maximum efficiency. HyperScale’s context from top to blocks and models from blocks to top allow signoff, ECO, and P&R tools to work independently with full chip timing at block and top levels. This enables fast turnaround time by allowing individual block designs teams to work in parallel while maintaining the signoff timing accuracy.
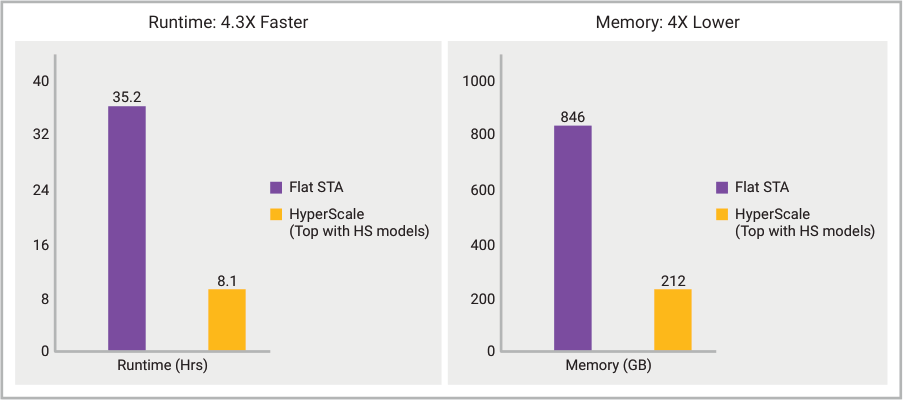
The results from running on a roughly 1 billion instance data center design are shown in the charts below. HyperScale enables running full chip timing signoff in about 8 hours using smaller 256 GB machines–4X faster and 4X lower memory vs. flat analysis. The chip team also reported that they found the accuracy of Hyperscale to be within 1 ps of flat STA runs.
The final key technology in Synopsys PrimeTime for faster and more efficient STA is HyperGrid, which enables Distributed STA (DSTA). With HyperGrid, users typically see up to 5X faster runtime and up to 5X reduction in memory consumption, with 100% match in quality of results (QoR) as compared to STA on a single server. HyperGrid automatically partitions the design, spawns a manager process and distributed worker processes, and merges everything at the end. This provides maximum flexibility and efficiency, enabling scaling across a variable number of servers. The speedup and memory savings provided by HyperGrid get even better as the number of partitions grow. The benefits to a chip project are substantial. On one customer project, full chip STA was reduced from one week to only two days. This eliminated 30 days of signoff runs, easing the tapeout schedule and saving considerable compute resources.
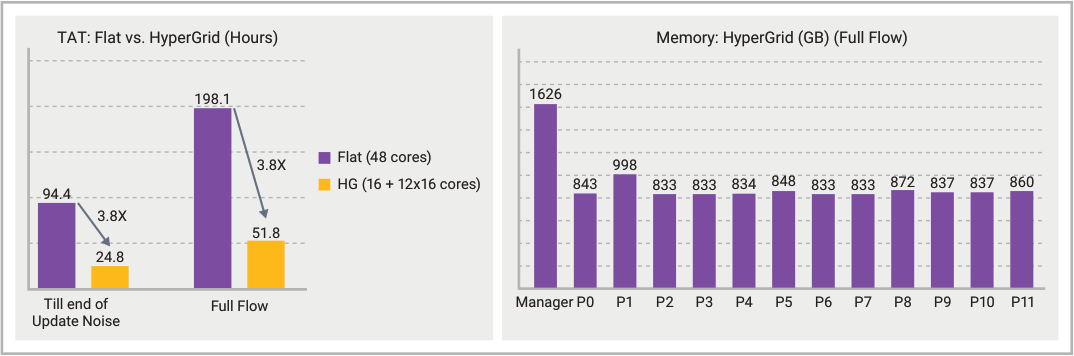
At the same recent SNUG conference, a team from Broadcom reported that they achieved a 3.8X runtime reduction by using HyperGrid on a design with more than 2 billion instances. As shown in the graph below, the twelve worker processes required less than 1 TB of memory each, so that the STA could run on smaller machines.
Transitioning from traditional flat full chip STA to HyperGrid is easy since existing Synopsys PrimeTime setup information is reused. This leads to a hassle-free DSTA flow setup, with minimal script changes. After the manager process merges results from the distributed worker processes, it generates the same reports as the traditional flow. Thus, any scripts or tools that analyze the reports can also be reused.
Advanced applications such as HPC and AI require massive chips, putting a great deal of pressure on STA tools and timing signoff. Three key technologies—multi-core scaling, HyperScale, and HyperGrid—provide a unique solution for today’s most advanced designs. There is simply no choice; designs with billions of instances cannot achieve timing signoff without multicore, hierarchical, and distributed STA. Synopsys PrimeTime maximizes compute resources, improves productivity, reduces timing TAT, and shrinks project schedules, all while maintaining QoR and timing accuracy.
 |
|
 |
 |
 |
 |
Leave a Reply