Cost- and memory-saving techniques to optimize AI performance with dynamic reconfiguration.

Large Language Models (LLMs) and Generative AI are driving up memory requirements, presenting a significant challenge. Modern LLMs can have billions of parameters, demanding many gigabytes of memory.
To address this issue, AI architects have devised clever solutions that dramatically reduce memory needs. Evolving techniques like lossless weight compression, structured sparsity, and new numerical formats (INT-4, FP4, ternary) can save substantial memory. However, for existing architectures, these solutions must be implemented in software, which comes with a severe trade-off – increased latency. Implementing these solutions in hardware provides the most efficient approach but lacks the adaptability required for emerging techniques.
Ultimately, to fully benefit from these memory-saving approaches, adaptable hardware is required. While the memory demands of LLMs and GenAI pose a major challenge, innovative solutions are emerging – though not without their own tradeoffs that must be carefully navigated.
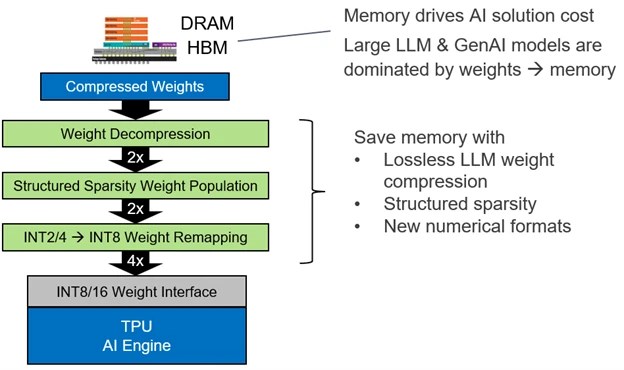
Fig. 1: Memory challenges with LLMs and generative AI.
Weight compression can dramatically reduce the memory footprint of LLMs without affecting model accuracy. Unlike quantization, which impacts both weights and activations, compression only affects the model’s weights. This preserves the model’s performance while significantly reducing memory requirements. For larger models with billions of parameters, a 4-bit weight compression can shrink memory needs by an order of magnitude.
There are many compression techniques, and all involve tradeoffs between memory reduction, processing time, and accuracy. Tools like who_what_benchmark can provide such analysis. Also consider that new algorithms continually evolve. Implementing this in adaptable hardware, such as Flex Logix eFPGA, allows designers to dynamically select the optimal compression option based on their dataset while providing deterministic latency with no loss in throughput.

Fig. 2: Adaptable hardware for weight decompression, structure sparsity and remapping.
Deploying sparsity is an emerging technique that, like compression, offers various methods with unique tradeoffs. Again, the optimal solution is dictated by the data format. Utilizing sparsity impacts not only performance and accuracy but also the specific implementation, as sparsity can vary across different networks. Ultimately, due to the “black box” nature of networks, adaptable hardware enables the deployment of the optimal solution.
While we’ve focused on fixed weight sizes so far, the more notorious optimization technique is quantization. This is significant because many networks can maintain performance even with lower-precision weights, often experiencing minimal accuracy loss from reduced weight sizes. However, as weight sizes decrease, the fixed data interface of the AI engine remains unchanged, necessitating data remapping. Given the variations discussed previously, this remapping step can differ across implementations. Fortunately, the challenges posed by this data shim can be easily resolved through the use of eFPGA adaptable hardware.
Another crucial consideration is that many models are sliced and processed in layers. Flex Logix eFPGA IP can reconfigure very quickly to support each layer uniquely and optimally – giving the highest efficiency possible. Flex Logix is already using these concepts in their own AI IP, InferX – optimized for edge vision AI and DSP.
The rapid evolution of high-performance AI models is remarkable. Typically, new operators and activation functions required for these models must be processed by a slower processor on most TPUs. However, with eFPGA technology, these post-processing tasks can be offloaded to existing hardware, resulting in a tremendous performance boost.

Fig. 3: Support output activations and new operator support with existing adaptable hardware.
Flex Logix’s scalable EFLX eFPGA IP, available across advanced process nodes, delivers optimal power, performance, and area (PPA) for any AI application. Moreover, the new eXpreso compiler from Flex Logix improves design implementation efficiency, providing up to 1.5x higher frequency, 2x denser LUT packing, and 10x faster compile times for all existing EFLX tiles and arrays.

Fig. 4: Scalable Flex Logix EFLX eFPGA IP.
If interested in learning more about Flex Logix IP and how it can provide longevity and cost savings to your AI solution, contact us at [email protected] or visit our website https://flex-logix.com.
 |
 |
 |
|
 |
|
 |
Leave a Reply