Three major changes in PCIe 6.0 that designers need to consider.

PCI Express (PCIe) 6.0 technology with key changes will bring about challenges that high-performance computing, artificial intelligence, and storage system-on-chip (SoC) designers will face. This article provides designers a summary of the major changes and how they can be handled to ensure a smooth and successful transition to PCIe 6.0.
The three major changes in PCIe 6.0 that designers need to consider are doubling of the data rate from 32 GT/s to 64 GT/s, a move to PAM-4 signaling and resulting error correction implications, and a change to fixed-sized FLITs.
The first and second changes are closely connected and are impacted by the nature of the channel over which PCIe 6.0 signals are expected to be transported.
In addition to these three changes, there are other new features that will be briefly covered, like a new low power state, L0p, intended to allow power/bandwidth scaling, and the expansion of the number of tags supported from 768 in PCIe 5.0 (10-bit tags) to 15,360 in PCIe 6.0 (14-bit tags).
When the data rate was doubled from 16 GT/s to 32 GT/s, the Nyquist frequency was also doubled from 8GHz to 16 GHz, making frequency-dependent losses much worse for PCIe 5.0 (Gen5) than 4.0 (Gen4). This, coupled with increased capacitive coupling (noise and crosstalk), made the PCIe 5.0 channel the most difficult NRZ channel. Had PCIe 6.0 tried to retain NRZ signaling, the Nyquist frequency would have increased to 32 GHz, and channel losses greater than 60dB, which is too large for realistic systems, hence the change from NRZ to PAM-4 signaling. Essentially, this change means transmitted and received signals now have four distinct voltage levels rather than two, as shown in figure 1.

Fig. 1: Eye diagrams shown on the same scale for (a) PCIe 5.0 32GT/s (NRZ signaling) showing 2 signal levels and a single eye, and (b) PCIe 6.0 64 GT/s (PAM-4 signaling) showing 4 signal levels and three distinct eyes.
Figure 1(a) shows an eye diagram for a PCIe 5.0 using NRZ signaling with the two voltage levels and a single eye. Figure 1(b) shows a PCIe 6.0 eye diagram using PAM-4 signaling with the four voltage levels and three eyes. Both signals in Figure 1 have the same Nyquist rate of 16 GHz and the same unit interval (UI). This means that they can essentially use the same PCIe 5.0 channels without the worse frequency-dependent losses one would encounter if using NRZ signaling for 64 GT/s with a Nyquist rate of 32 GHz. This is why Ethernet moved to PAM-4 signaling for 56G and 112G, and why PCIe 6.0 has now moved to PAM-4. There is no more loss of signal, but the four voltage levels of PAM-4 encode two bits in a single UI versus a single bit for NRZ, resulting in double the data rate. This sounds great, however, there is a significant tradeoff. Since the overall voltage swing of the transmitter (TX) has not increased, the available voltage for each eye in the PAM-4 system is only 1/3 of that for NRZ. So, any noise the signal encounters between TX and receiver (RX) is much more damaging to the signal integrity.
The change to PAM-4 makes the job of the RX much harder as the eye is not only much smaller in the voltage domain (~ 1/3), but it is also much smaller in the time domain since so many transitions have to fit into the single UI. As shown in Figure 1, this is quite evident; the green arrow at the bottom of figure 1(b) shows the comparative width of the NRZ eye, revealing that the eye width for PAM-4 is significantly smaller than that of the NRZ eye. So, clock and data recovery are harder with PAM-4, requiring a better RX design. Most designs for PAM-4, including upcoming PCIe 6.0 designs, will have an analog-to-digital converter (ADC) in the RX to better handle PAM-4’s multi-level signaling requirement coupled with the legacy NRZ support. This means that digital filtering is wide open, and the specific digital signal processing (DSP) algorithms utilized by one RX vs another, coupled with the careful balance of analog and digital equalization for different channels, will differentiate PHY performance. In addition, the narrower PAM-4 eyes mean that the TX jitter performance needs to be much better for PCIe 6.0 than it was for PCIe 5.0 by about 2x, and these factors should be carefully considered by designers.
The move from NRZ to PAM-4 signaling also impacts package and board designs significantly because the change to four signaling levels results in an immediate degradation of 9.6dB in the Signal to Noise Ratio (SNR), making it more critical to properly manage noise, crosstalk, and return loss in package and board designs than it was for PCIe 5.0, even though the Nyquist rate is the same. This increased noise sensitivity means that the bit error rate (BER) of 1e-12 that we are used to for PCIe is not feasible and Forward Error Correction (FEC) is needed, since the BER for the PAM-4 signaling will be several orders of magnitude higher than 1e-12, with the target being 1e-6 for the First Bit Error Rate (FBER). In other standards, like Ethernet, a strong FEC has been used to get to an acceptable BER, but with a penalty of significant additional latency on the order of 100ns, which is not acceptable for PCIe.
Since FEC latency and complexity increases with the number of symbols that are being corrected, and because of the very aggressive latency goals of PCIe 6.0, a lightweight FEC is used and is coupled with the retry capability of PCIe that uses Cyclic Redundancy Codes (CRC) to detect errors so that packets can be resent or retried. The lightweight FEC for PCIe 6.0 can result in a retry probability on the order of 1e-6, and when coupled with a stronger CRC, the overall system can provide robust, near error-free performance with only a very small (typically ~ 2ns) impact to the round trip latency. This means that designers can design with essentially the same latency expectations they are used to from PCIe 5.0, and for many cases, like transaction layer packets (TLP) sizes greater than 128 Bytes (32 DW), an actual latency improvement over PCIe 5.0 will be seen.
Another important consideration for designer is the move to FLITs as the unit of data exchange instead of the variable sized TLPs. This is necessary due to the change to PAM-4 encoding and the need for FEC to enhance the BER to an acceptable level so that the CRC and retry mechanism can yield an acceptable error rate and system latency. FEC only works on fixed sized data packets, so PCIe 6.0 has adopted 256-Byte FLITs as the standard sized data transfer unit. A desire to retain the reach of PCIe 5.0 with existing channels leads to the change to PAM-4, which requires the addition of FEC, which in turn requires a move to FLITs. Using FLITs has system ramifications, as some FLITs may have data from multiple TLPs, while other FLITs may contain only part of a TLP, and the underlying TLPs still can vary in size from 0 to 4096B (1024 DWORDS).
Another ramification is that once a device enters FLIT mode, for example by negotiating a PCIe 6.0 link which must support FLITs, it needs to stay in FLIT mode, regardless of what happens to the link quality. So, if the link speed needs to be lowered due to channel instability, the newly negotiated lower data rate will retain FLIT mode. This means in PCIe 6.0 there are FLIT modes for all possible speeds that need to be supported.
With the new FLIT modes introduced in PCIe 6.0 there are changes to the TLP and data layer packet (DLP) header formats that need to be understood and properly handled by the application. For example, for PCIe 6.0, the FLITs include their own CRC, so the data link layer packets (DLLPs) and TLPs no longer need individual CRC bytes like they did in PCIe 5.0 and previous generations. Also, with the fixed size of the FLITs, there is no need for the PHY layer framing tokens used in previous generations (non-FLIT modes). This leads to improved bandwidth efficiency compared to PCIe 5.0.
PCIe 6.0 introduces a new low power state called L0p that allows PCIe 6.0 links to reduce power consumption by scaling the bandwidth usage without interrupting the data flow. In previous generations, in order to change link width, traffic was interrupted for several microseconds as the entire link retrained, but L0p allows the link to shut down lanes, thereby reducing power, while always keeping at least one lane active, even as other lanes undergo link training. This new low power mode is available in FLIT mode only, while L0s supports non-FLIT modes.
This new low power mode is symmetric, meaning that TX and RX scale together, and it is also supported for retimers that support FLIT mode. PHY power savings for idle lanes during L0p are expected to be similar to powering down the lanes.
To achieve the best performance in a PCIe system, designers need to determine the maximum number of outstanding non-posted requests (NPR) that must be handled by their system to keep the data flowing, which is a function of the payload size as well as the total round trip time (RTT). This number translates into the number of tags that are available and is a property of the controller that must be set correctly based on the system requirements. For PCIe 6.0, with another doubling of the data rate, the previous 768 tag limit is not nearly enough, so the number of tags is increasing dramatically to a new maximum of 15,360, based on 14-bit tags. This can enable efficient performance, even with larger round-trip times and has plenty of margin to allow for even faster data rates in the future.
Figure 2 illustrates the number of tags that are needed for PCIe 4.0, 5.0 and 6.0 data rates for various RTTs to maintain maximum throughput for 256B payloads with 32B minimum read request size. As shown in figure 2, the 768-tag limit from PCIe 5.0 is not nearly enough to maintain performance for most PCIe 6.0 systems. This should be simulated and verified during the configuration of a PCIe 6.0 controller as part of a SoC design to ensure expected performance can be achieved.
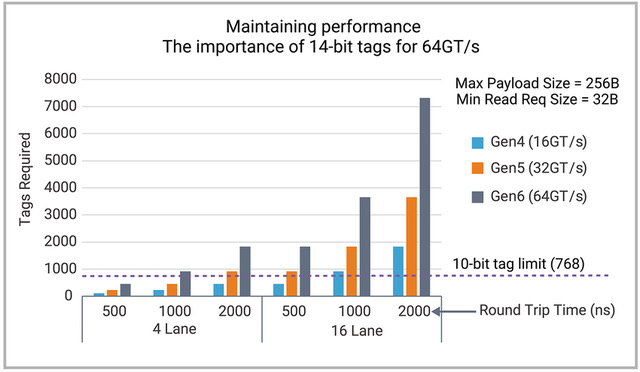
Fig. 2: Number of tags needed to achieve maximum throughput for PCIe 4.0 through PCIe 6.0 links.
A second factor to consider is how to make sure the application can efficiently utilize the massive available bandwidth of PCIe 6.0. Typically, an application has connected to PCIe via the controller with 3 separate interfaces: one each for posted, non-posted, and completion transactions. For 64 GT/s PCIe 6.0, analysis of various cases shows that single interfaces will lead to significant loss in link utilization or bandwidth efficiency (achieved vs theoretical bandwidth). The problem is worse for smaller datapath widths and smaller payload sizes.
As shown in figure 3, the transmit link utilization is shown for various PCIe 6.0 datapath widths and payload sizes for both a traditional single application interface, and for dual application interfaces (for posted transactions). In the case of 32 Byte payloads for a 1024b datapath, the degradation in link utilization resulting from using a single posted interface instead of two is 54%. This means that in this case, using a controller with a single application interface would result in performance equivalent to PCIe 5.0.

Fig. 3: Using multiple application interfaces to improve PCIe 6.0 link utilization.
To achieve the best performance, lowest latency, and simplified integration, it is advantageous to implement a complete PHY and controller IP solution from a single vendor. When that is not possible, the specifics of the PIPE interface are critical. The PIPE 5.x interface specification does not support PCIe 6.0, so the newer version, PIPE 6.0, must be specified. It now appears that most designs for PCIe 6.0 will adopt the SerDes Architecture PIPE interface based on the new PIPE 6.0 specification. This simplifies the PHY design and enables the PCIe 6.0 PHYs to support the low-latency requirements of CXL 3.0 when it comes out.
There continues to be a tradeoff between the datapath width and the frequency at which timings must be closed at the PIPE interface in PCIe 6.0. For applications requiring the maximum PCIe 6.0 bandwidth and a 16-lane configuration, there are only two realistic options. To keep timing closure reasonable at 1GHz requires using 64b PIPE, which, in turn, requires a 1024b PCIe 6.0 controller architecture (16 lanes x 64b = 1024b). This is a new feature for PCIe 6.0, as there have been no 1024-bit architectures available for prior PCIe generations.
The other option is to use 32-bit PIPE and stick with a 512-bit architecture. This means closing timing at 2GHz at the PHY controller interface. While this is unlikely to be the first choice for most SoC designers, some designers trying to achieve the minimum latency in a very fast CMOS process may opt for this option, as it halves the cycle time of the bit clock, offering reduced latency compared with 1GHz timing.
For production devices, manufacturing testing at 64 GT/s requires fast tests that can verify links, typically using built-in loopback modes, pattern generators and receivers that are incorporated into the PHY and controller IP. Supporting loopback in a PHY for PAM-4 is more complex than for NRZ, but equally important, and should be considered as part of a testability solution.
For debug and quality monitoring in actual silicon, being able to monitor the FBER within the silicon can also be very beneficial to get a look at the real link quality of a system. This can be used in conjunction with the built-in scope capability typically incorporated into PCIe 6.0 PHY IP to get a more detailed understanding of what may be happening between a TX and RX.
For more robust system testing for a new specification like PCIe 6.0, it is important to have built in controller support for debug, error-injection, and statistical monitoring capability. This helps ensure that firmware and software can be developed correctly to anticipate any potential real-world system issue that may be encountered.
While PCIe 5.0 is gaining traction and being adopted in mainstream designs, the industry is eagerly awaiting the introduction of PCIe 6.0. The good news is that PCIe 6.0 brings higher performance and a slew of new features, including a 64 GT/s data rate, the use of FLITS with throughput and latency benefits, and a new low power state, L0p, enabling true bandwidth scaling to reduce power. However, these changes introduce considerations that designers need to understand before deciding on migrating to the new PCIe 6.0 specification. Synopsys can make this transition much easier with both DesignWare IP for PCIe 5.0, which has been leveraged by customers in over 150 designs, and PCIe 6.0 which was recently introduced. Synopsys is an active contributor to the PCI-SIG work groups helping to develop the PCIe specification across all the generations.
Additional Resources
 |
|
 |
 |
 |  |
 |  |
Leave a Reply