The actual time may be more of a fuzzy risk assessment than a clear demarcation.

Even with the billions of dollars spent on R&D for EDA tools, and tens of billions more on verification labor, only 30% to 50% of ASIC designs are first time right, according to Wilson Research Group and Siemens EDA.
Even then, these designs still have bugs. They’re just not catastrophic enough to cause a re-spin. This means more efficient verification is needed. Until then, verification teams continue to challenge designs with every manner of stimulus they can throw at it. But there isn’t an exact science to indicate when to stop verifying.
Re-spins cause pain on a number of levels. A re-spin at 28nm may add up to $500,000 for the cost of a new mask, while a re-spin at a smaller geometry may cost up to $1 million. Then there is the issue of losing a target market. If a chipmaker is servicing a billion-dollar market, and is late by three months on a product lifecycle that lasts only 24 months, the lost revenue can be devastating. But when to stop isn’t always obvious.
“For verification to be considered complete, a solid understanding of verification coverage must be had first,” said Nicolae Tusinschi, product manager for design verification solutions at OneSpin Solutions. “It is hard to meet IC integrity standards, which is making sure the design operates as intended, is safe, trusted, and secure, without knowing if or where there are gaps in verification. You can’t reach sign-off with confidence without precise coverage analysis. What’s needed is a fast and precise measure of progress and coverage improvement.”
The verification task is compounded by different levels of challenges, depending on where the developer sits in the ecosystem. “If you are a systems company that designs the silicon, package, board, system, and the software, you actually have the luxury to have full control,” said Michael Young, director of product marketing at Cadence. “But imagine that you are a customer at a major chip company, or you are designing a certain chip that goes into a PCIe card that plugs into a computer motherboard. It’s very difficult to understand the system scenario. In order to reduce the risk, and the cost of a re-spin, and to find customer bugs, the concept of shift left has been coming into play. All the activities that used to be done at the hardware level are being shifted into hardware/software. And this hardware/software development is being done at an SoC level, and SoCs are being done as early as possible. The challenge here is that the simulator is not delivering the same speed-ups as in the past, so a lot of people are shifting left either emulation or prototyping systems to do the additional work, and moving more workload onto verification.”
This requires having a clear picture of what needs to be verified. “You can only define and verify what you can specify,” Young said. “What you cannot specify is what’s going to kill you. Once you start the specification, if you’re not doing it right — or your device has to live in a foreign environment that’s not under your control — your risk is much higher.”
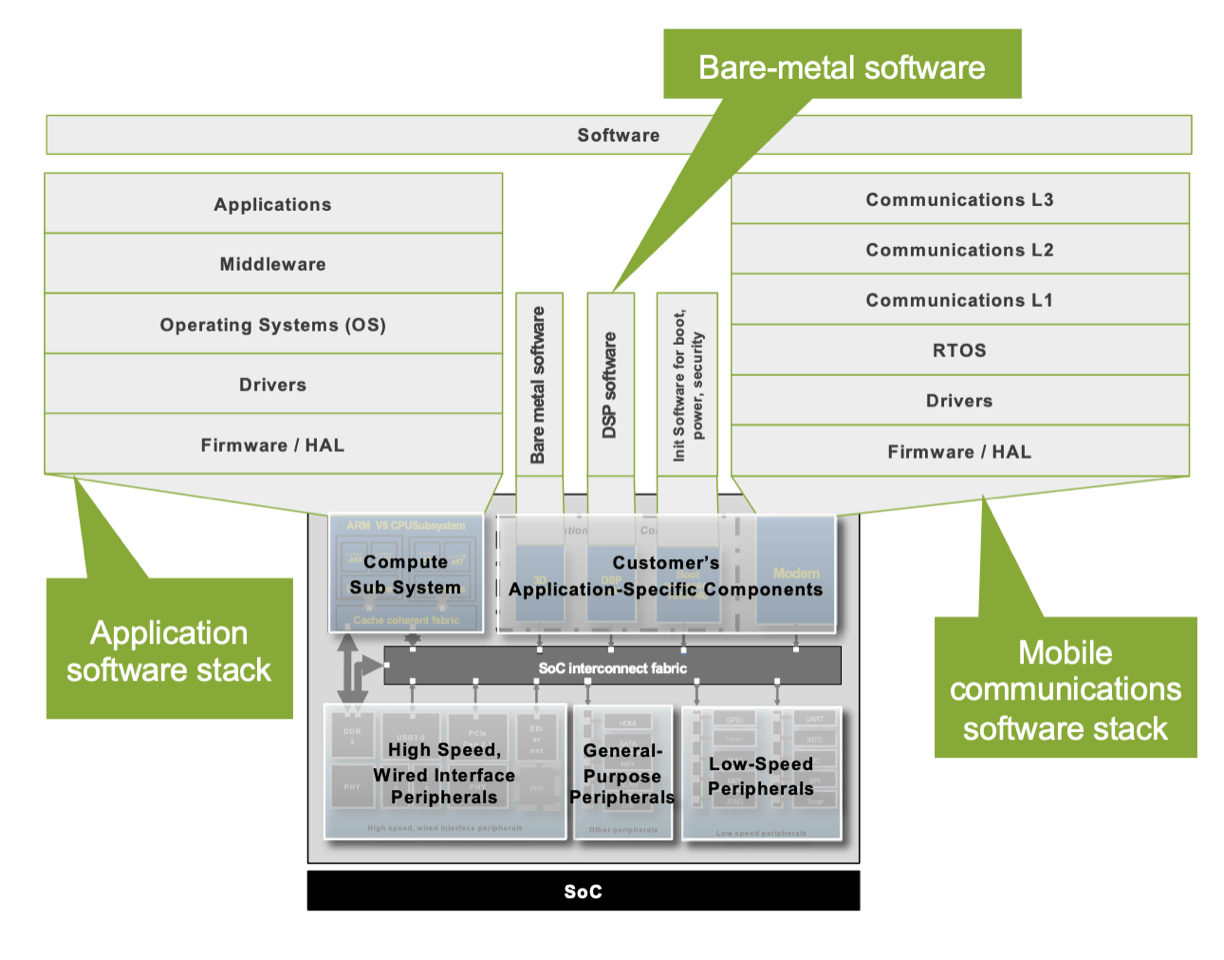
Fig. 1: System-centric view of SoC. Source: Cadence
When will it be done?
So what exactly does “done” mean when it comes to verifying a chip or a subsystem or a package?
“Nowadays, the adoption of functional and code coverage is a must — you have to have it, and you have to invest in it,” said Hagai Arbel, CEO of Vtool. “More and more companies are doing it, and following it quite strictly, and yet the percentage of chips that are first time right is decreasing. If you inspect the chips that had bugs or bugs critical enough for a re-spin, they followed the state-of-the art definition of ‘done’ in verification, which is functional coverage and code coverage 100%. You will see quite a few of them. That means it’s not helping.”
In fact, highly-skilled verification engineers find critical bugs even after 100% functional coverage, and 100% code coverage have been reached, Arbel said. “How do they find them? How do they even know that 100% coverage it is not enough? Every good verification engineer develops a hunch such that, ‘It says it is covered, but I am not at ease. Something doesn’t look right to me.’ Really good verification engineers have some kind of sixth sense to that. They just know. And if you are a very good verification manager, you develop this sense about other people’s verification. If you review the coverage, I’m not saying that it’s not important. But it’s not enough yet to be sure, or to even get close to that. In addition to code coverage and functional coverage, alternative metrics, such as the quality of the verification efforts, should be taken into account. Still, how safe can you be doing all of that? Some companies are really struggling with this. Some companies have managed to develop better processes and internal processes, but as an EDA industry we are not even close to providing a good-enough solution. There is huge opportunity here to work to formalize a way to log information and make conclusions.”
Boiled down to its essence, verification is a risk management exercise. “If you look at the differences between FPGA and ASIC, and the way they approach verification, from a risk management perspective you start to see why they treat things differently,” said Neil Hand, director of marketing for IC verification solutions at Siemens EDA. “In FPGA, they take more risks because they can fix it afterwards, whereas in ASIC you can’t. So if you start to look at your verification as a risk management exercise, it no longer becomes a question of when you’re done, because you can never be done. The question then becomes, ‘When have I hit my risk tolerance? When have I gotten to the point that I feel comfortable signing off on this design?’”
What can help is having data and tools to close coverage quicker. “You have coverage, which is how a lot of people measure risk today, but coverage is not the whole picture,” Hand said. “You may have coverage holes. You may not define coverage. There may be a lot of gaps. But if there is a set of metrics you’ve defined, you can measure against those. Also, tools and technologies can be utilized to determine if those metrics are good. You could have a coverage methodology where you’ve defined 1,000 coverage points. You hit all of those 1,000 coverage points, but those 1,000 coverage points only hit 10% of your design. So what is your risk exposure?”
These are issues that must be addressed. But it’s not that simple. Defining a risk boundary is a moving target because it depends on the design, and the context of that design within a system and interactions with other systems.
“There is a tradeoff, but for every chip it’s different,” he said. “Acceptable risk is going to be different for every design. What you have to do is give the tools, whether it’s through verification management, requirements management, coverage traceability, or through machine learning, to understand what have you looked at versus what have you not looked at. We often become blind when we’re looking in a particular area. We don’t see the monster over our right shoulder that is ready to pounce. We can use machine learning techniques to identify that you’re doing all the right stuff, but that monster is still there.”
This is particularly true in heterogeneous systems, which are increasingly common as Moore’s Law runs out of steam. That has forced design teams to use new architectures as the differentiator for various applications and markets. This has opened the door both for custom accelerators, and it has driven some of the momentum for RISC-V. But it also has made designs much more complicated and more difficult to verify.
“We are seeing this in designs with open-source cores, where there are new corner cases we’ve never seen before,” said Louie de Luna, director of marketing at Aldec. “It’s the same for verification. We’re seeing new UVM use cases, and we’re catching a lot of bugs.”
De Luna noted this also is driving a lot of related activity, as well, such as virtual modeling and multi-core debug. In effect, engineers are using everything at their disposal to deal with the rising complexity.
Not as simple as it sounds
While much of this is design and use-case dependent, there also is growing consensus that verification needs to be a continuous process rather than just a single step in the design flow.
“A very simple answer to this question is, ‘Verification is done when you prove that the design does not have any flaws,'” said Shubhodeep Roy Choudhury, CEO of Valtrix Systems. “That’s when you can call your verification done. But that’s an NP hard problem, and it never can get done. You have the space. The amount of tests and the coverage are infinite so technically you can never really get done with your verification activity.”
There are a number of other factors to consider, as well. “You have to ensure that the power and performance goals are met, and that your end use case toward what you’re designing is working as expected,” Roy Choudhury said. “Some of these criteria can be used to tell that verification is close to getting done, like when you have all your code, and code coverage and functional coverage are hitting numbers acceptable by your design and verification teams. Typically, all these designs are iterations on top of some previous design that you already have in place, so a lot of effort from a verification point of view goes into developing tests that exercise the design deltas, and the interaction of the new features with the legacy features. This means a lot of effort goes into writing tests. You need to ensure that those tests are working as intended, without any faults or failures. You need good verification engineers to tell whether the intent has been met, and the design is behaving as expected. There are a number of activities, such as some parts of the design where you can apply formal models and get proof that the design is really not having any flaws, that also can be used wherever it can be applied.”
This can be taken step by step. “In functional verification, anytime we are asked to verify a feature, everything starts with test planning,” he said. “So we identify the different changes that are going into the design, and then we create hundreds of scenarios, which are required to ensure that a particular feature is working as expected. Then we take some time before the design is even available to write tests, making sure they are working fine on virtual models or functionally accurate simulators. Once the testers are ready and the design is available, we get it running and try to ensure that there are no failures. At a point toward the end of the program, usually, the rate of design bugs can be taken as a good indicator of how the overall verification is doing. It will tend to plateau when you’re getting done with the entire verification task.”
All of this has to go hand in hand with functional and code coverage tools. Every time a new version of the design is available, there usually is phase involving code and functional coverage analysis to make sure that all intended the scenarios are getting hit. These are the indicators that are used to ensure the design is verified.
Another consideration here is deciding what to measure, and how to measure it. Simon Davidmann, CEO of Imperas Software, pointed to a recent RISC-V project as an example. “We were just involved with a project on a 32-bit RISC core with OpenHW Group, and one of the first things that happened was a test plan was written that said, ‘These are the bits of the design that are well tested already, these are the new bits, these are the bits we worry about, and these are the bits which probably have things hidden in the wings that we’re not aware of.’ They came up with the test plan, put resources in, and could say, ‘This is bit of the design where we’re going to use directed testing, for this bit we’re going to use random. For this bit we’re going to use asynchronous step-and-compare testing, and for this bit actually we’re going to use formal to test how things come in and out of debug mode, which is traditionally quite a hard thing. You basically look at the design challenge that you’ve got and work out what you know, what you don’t know, and what the risks are. What level do I have to get to before I’m happy with ‘good enough,’ because you can’t prove there’s no bugs? You can only say it’s good enough to ship.”
Sharing knowledge
Another obstacle, which is an important aspect of the entire design and verification process, is how to share this with other team members, Vtool’s Arbel said. “Often, more than one person is involved. I am a verification engineer and I think I have a problem. I’m sending it to the designer. He’s sending it back. The architect gets in between, and the software team gets involved. There are many people are involved, mostly shifting the stick from one to another, not being able to really collaborate and solve this together. Verification engineers must learn how to use their combined knowledge to be more efficient. Today, debug is a lonely road — lonely in the sense that it’s hard to get people to help you, but it’s also very hard to teach.”
To this point, Roy Choudhury said it helps to thoroughly document whatever has been done. “If you have good records of your entire verification activity, it helps quite a bit. In one of my previous companies, we used to keep logs of the entire post-silicon validation process that used to be done on the server designs that we used to verify. It was highly detailed. For example, we used to have area owners for the load store unit, for CPU tests, etc., and each one had a big set of legacy tests, and they were allocated N number of hours to test the design whenever the tester was available. Over time, we had records of all of these verification activities. Depending on the new features coming in, for example, if there were lots of features happening, then the load store unit area owner, for example, would get more hours to test. After that point, it becomes quite seamless if you have everything very well documented, if you have the entire historical plan with you.”
Of course, some amount of knowledge is required, he noted. “You need to know the tools, and have the methodologies in place to do better, along with the efficiencies that can be put into place such as functional verification. This a big area, and all of us are interested in it to ensure that the entire stimulus that we have is completely portable so that we can use it seamlessly across multiple phases of the design, be it simulations of the silicon or otherwise. This will enable a great amount of reuse, and will of course lead to much higher efficiency.”
OneSpin’s Tusinschi noted that a fast and precise measure of progress and coverage improvement can be achieved with formal-based mutation analysis, model-based fault injection, and precise mapping to the source code. “The result is the reliable identification of verification gaps and blind spots. Of course, an optimum solution would be to bring all verification metrics like those from both simulation and formal into a single view for greater understanding of the overall verification effort and progression,” he said.
Conclusion
In the end, you’re done when you feel you’re done, Imperas’ Davidmann said. “You have to put measurements in place, you have to analyze. When there are issues, you need to understand what the processes are. It’s all about experience. You need a lot of experience to work out how to do all of this.”
Further, new techniques are emerging with teams looking to use AI to help when generating tests. “You can use AI to see how effective the tests are, see where the test is explored in the design, and what would be a better way to do things so that it can help improve the quality of the testing that you’re doing. This can, if done right, save the amount of time it takes to get all your tests done and regression test, and to improve the quality of things. We’re in the early stages of using AI to help us with verification at the moment,” he noted.
Finally, Cadence’s Young stressed that to determine when verification is done. “You basically try to get the coverage to 100%, and run as much as possible before your boss tells you that if you don’t tape out, the team is going to be in jeopardy. This is obviously experienced-based, but you need to use spec-based coverage models. You need to run as many regression tests as possible. You’re looking to make sure that even if there are some errata discovered, it can be handled through software, rather than having to do a re-spin.”

 |
|
 |
 |
 |
 |
Leave a Reply