The backbone of computing architecture for 75 years is being supplanted by more efficient, less general compute architectures.

In an era dominated by machine learning, the von Neumann architecture is struggling to stay relevant.
The world has changed from being control-centric to one that is data-centric, pushing processor architectures to evolve. Venture money is flooding into domain-specific architectures (DSA), but traditional processors also are evolving. For many markets, they continue to provide an effective solution.
The von Neumann architecture for general-purpose computing was first described in 1945 and stood the test of time until the turn of the Millennium. The paper John von Neumann wrote described an architecture where data and programs are both stored in the same address space of a computer’s memory — even though it was actually an invention of J. Presper Eckert and John Mauchly.
A couple reasons explain the architecture’s success. First, it is Turing Complete, which means that given enough memory and enough time, it can complete any mathematical task. Today we don’t think much about this. But back in the early days of computing, the notion of a single machine that could perform any programmed task was a breakthrough. Passing this test relies on it having random access to memory.
Second, it was scalable. Moore’s Law provided the fuel behind it. Memory could be expanded, the width of the data could be enlarged, the speed at which it could do computations increased. There was little need to modify the architecture or the programming model associated with it.
Small changes were made to the von Neumann architecture, such as the Harvard architecture that separated the data and program buses. This improved memory bandwidth and allowed these operations to be performed in parallel. This initially was adopted in digital signal processors, but later became used in most computer architectures. At this point, some people thought that all functionality would migrate to software, which would mean an end to custom hardware design.
End of an era
Scalability slowed around 2000. Then, Dennard scaling reared its head in 2007 and power consumption became a limiter. While the industry didn’t recognize it at the time, that was the biggest inflection point in the industry to date. It was the end of instruction-level parallelism. At first, it seemed as if the solution was to add additional processors. This tactic managed to delay the inevitable, but it was just a temporary fix.
“One of the problems is that CPUs are not really good at anything,” says Michael Frank, fellow and system architect at Arteris IP. “CPUs are good at processing a single thread that has a lot of decisions in it. That is why you have branch predictors, and they have been the subject of research for many years.”
But in an era of rapid change, any design that does not expect the unexpected may be severely limited. “Von Neumann architectures tend to be very flexible and programmable, which is a key strength, especially in the rapidly changing world of machine learning,” says Matthew Mattina, distinguished engineer and senior director for Arm’s Machine Learning Research Lab. “However, this flexibility comes at a cost in terms of power and peak performance. The challenge is to design a programmable CPU, or accelerator, in a way such that you maintain ‘enough’ programmability while achieving higher performance and lower power. Large vector lengths are one example. You’re amortizing the power cost of the standard fetch/decode portions of a CPU pipeline, while getting more work done in a single operation.”
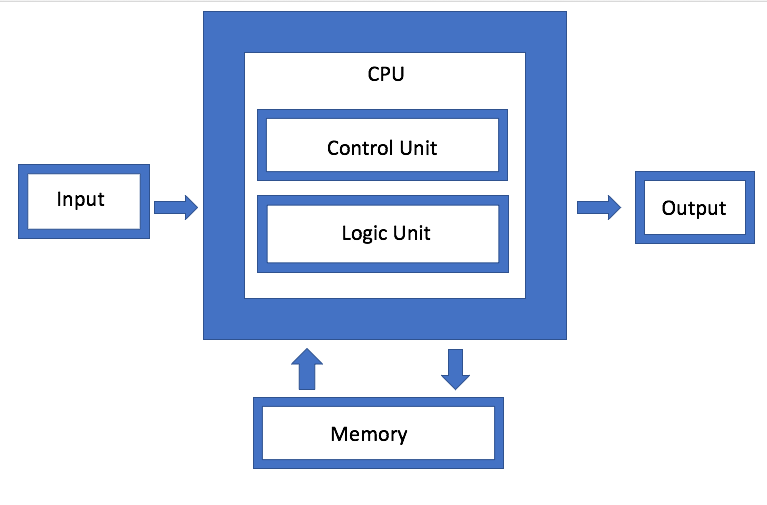
Fig. 1: The von Neumann architecture, first described in the 1940s, has been the mainstay of computing up until the 2000s. Data and programs are both stored in the same address space of a computer’s memory. Source: Semiconductor Engineering
Accelerators provide a compromise. “Accelerators serve two areas,” says Arteris’ Frank. “One is where you have a lot of data moving around, where the CPU is not good at processing it. Here we see vector extensions going wider. There are also a lot of operations that are very specific. If you look at neural networks, where you have non-linear thresholding and you have huge matrix multiplies, doing this with a CPU is inefficient. So people try to move the workload closer to memory, or into specialized function units.”
To make things even more complicated, the nature of data has changed. More of it is temporal. The temporal aspects of data were first seen with audio and video. But even a couple decades ago, a single computer could keep up with the relatively slow data rates of audio. Video has presented much greater challenges, both for processing and memory.
The memory bottleneck
Memory access is expensive in terms of time and energy. Caches address this problem by exploiting data locality. “Most silicon designs use various technologies for reducing power consumption,” says Anoop Saha, market development manager for Siemens EDA. “Improving memory accesses is one of the biggest bang-for-the-buck architecture innovations for reducing overall system-level power consumption. That is because an off-chip DRAM access consumes almost a thousand times more power than a 32-bit floating point multiply operation.”
Ever-more complex caching schemes have been developed since then in an attempt to bring the memory closer to the processor. But accessing a cache still consumes 200X the power compared with the same variable being stored in a register.
Put simply, memory has become the limiter. “For some applications, memory bandwidth is limiting growth,” says Ravi Subramanian, vice president and general manager for Siemens EDA. “One of the key reasons for the growth of specialized processors, as well as in-memory (or near-memory) computer architectures, is to directly address the limitations of traditional von Neumann architectures. This is especially the case when so much energy is spent moving data between processors and memory versus energy spent on actual compute.”
The rapid emergence of AI/ML is forcing change in the memory architecture. “The processors may be custom, but you need the SRAM to be local,” says Ron Lowman, strategic marketing manager for IoT at Synopsys. “For AI applications, you want to execute and store as much of the weights and coefficients as close to the MACs as possible. That is what eats up the power consumption. Multi-port memories are very popular for AI. This means you can parallelize reads and writes when you are doing the math. That can cut the power in half.”
Bob Beachler, VP of Product for Untether AI, puts some hard figures on that. “The coefficients are generally static – so why move them so much? Rather, using at-memory computation, where the coefficients can be stored in a memory array *right next to* the processing element, dramatically decreases the travel distance. And the memory array can be tuned to drive a shorter distance, something you can’t do with large/deep on-chip caches. This reduces the overall power by about 6X and 50% of the power is in the compute, 50% is in the movement of data.”
This kind of change in memory architecture comes with a large penalty. “The challenge is that in the past, people had a nice abstract model for thinking about computing systems,” says Steven Woo, fellow and distinguished inventor at Rambus. “They never really had to think about memory. It came along for free and the programming model just made it such that when you did references to memory, it just happened. You never had to be explicit about what you were doing. When new kinds of memories enter the equation, you have to get rid of the very abstract view that we used to have to make them really useful.”
This needs to change, however. “Programmers will have to become more aware of what the memory hierarchy looks like,” Woo says. “It is still early days, and the industry has not settled on a particular kind of model, but there is a general understanding that in order make it useful, you have to increase the understanding about what is under the hood. Some of the programming models, like persistent memory (PMEM), call on the user to understand where data is, and to think about how to move it, and ensure that the data is in the place that it needs to be.”
At the heart of AI applications is the multiply accumulate function (MAC), or dot product operation. This takes two numbers, multiplies them together and adds the result to an accumulator. The numbers are fetched from and stored to memory. Those operations are repeated many times and account for the vast majority of the time and power consumed by both learning and inferencing.
The memory needs of AI are different from those of GPUs or CPUs. “It is important to optimize the algorithm to improve data locality so as to minimize data movement,” says Siemens’ Saha. “These choices are dependent on the specific workloads that the chip is designed to run. For example, image processing accelerators use line buffers (which works on only a small sample of an image at a time), whereas a neural network accelerator uses double buffer memories (as they will need to operate on the image multiple times).”
For example, with an AI accelerator that processes layer-by-layer, it is possible to anticipate what memory contents will be required ahead of time. “While layer N is being processed, the weights for layer N+1 are brought in from DRAM, in the background, during computation of layer N,” explains Geoff Tate, CEO of Flex Logix. “So the DRAM transfer time rarely stalls compute, even with just a single DRAM. When layer N compute is done, the weights for layer N+1 are moved in a couple microseconds from a cache memory to a memory that is directly adjacent to the MACs. When the next layer is computed, the weights used for every MAC are brought in from SRAM located directly adjacent to each cluster of MACs, so the computation access of weights is very low power and very fast.”
Domain-specific architectures often come with new languages and programming frameworks. “These often create new tiers of memory and ways to cache it or move the data so that it is closer to where it needs to be,” says Rambus’ Woo. “It adds a dimension that most of the industry is not used to. We have not really been taught that kind of thing in school and it is not something that the industry has decades of experience with, so it is not ingrained in the programmers.”
Times are changing
But that may not be enough. The world is slowly becoming more conscious of the impacts of using arbitrary amounts of energy, and the ultimate damage we are doing to our environment. The entire tech industry can and must do better.
Academics have been looking at the human brain for inspiration, noting that pulsing networks are closer to the way the brain works than large matrix manipulations against a bank of stored weights, which are at the heart of systems today. Pulses fire when something important changes and does not require completely new images, or other sensor data, every time the equivalent of a clock fires. Early work shows that these approaches can be 20X to 50X more power-efficient.
Mixed-signal solutions are a strong candidate. “There are designs that are closer to mixed-signal designs that are looking at doing computation directly within the memories,” says Dave Pursley, product management director at Cadence. “They are focusing on the elimination of data movement altogether. Even if you read a lot of the academic papers, so much of the research used to be about how do you reduce the amount of computation and now we are in a phase where we are looking at the reduction in data movement or improve locality so that you don’t need such massive amounts of storage and those very costly memory accesses in terms of power.”
New computation concepts are important. “The idea is that these things that can perform multiply-accumulates for fully connected neural network layers in a single timestep,” explained Geoffrey Burr, principal RSM at IBM Research. “What would otherwise take a million clocks on a series of processors, you can do that in the analog domain, using the underlying physics at the location of the data. That has enough seriously interesting aspects to it in time and energy that it might go someplace.”
Analog may have another significant advantage over the digital systems being used today. Object detection systems in today’s automobiles often cannot handle the unexpected. “Neural networks are fragile,” said Dario Gil, vice president of AI and IBM Q, during a panel discussion at the Design Automation Conference in 2018. “If you have seen the emergence of adversarial networks and how you can inject noise into the system to fool it into classifying an image, or fooling it into how it detects language of a transcription, this tells you the fragility that is inherent in these systems. You can go from something looking like a bus, and after noise injection it says it a zebra. You can poison neural networks, and they are subject to all sorts of attacks.”
Digital fails, analog degrades. Whether that is true for analog neural networks, and whether they can be more trustworthy, remains to be seen.
Conclusion
There always will be an element of control in every system we create. As a result, the von Neumann architecture is not going away. It is the most general-purpose computer possible, and that makes it indispensable. At the same time, a lot of the heavy computational lifting is moving to non-von Neumann architectures. Accelerators and custom cores can do a much better job with significantly less energy. More optimized memory architectures are also providing significant gains.
Still, that is just one design tradeoff. For devices that cannot have dedicated cores for every function they are likely to perform, there are some middle ground compromises, and the market for these remains robust. The other problem is that the programming model associated with the von Neumann architecture is so ingrained that it will take a long time before there are enough programmers who can write software for new architectures.
Related
The Challenges Of Building Inferencing Chips
As the field of AI continues to advance, different approaches to inferencing are being developed. Not all of them will work.
Will In-Memory Processing Work?
Changes that sidestep von Neumann architecture could be key to low-power ML hardware.
PCIe 5.0 Drill-Down
The new PCI Express standard, why it’s so important for data centers, how it compares with previous versions of the standard, and how it will fit into existing and non-von Neumann architectures.
Solving The Memory Bottleneck
Moving large amounts of data around a system is no longer the path to success. It is too slow and consumes too much power. It is time to flip the equation.

 |
|
 |
 |
 |  |
 |  |
You should look into GSI Technology which is addressing this problem via their APU (associative processing unit) architecture. This will be a key product for similarity search, especially in applications like ecommerce
Looks like you Journalists are getting tired of bashing Moore’s Law, and have now found a new Scientific Genius to bash, the grand old Mathematician Johnny von Neumann of Princeton who drove a Sports Car ! Give him a break !! Old von Neumann had brushed aside the vague architectures Turing had seeded at IAS, Princeton during his stay there and in 1944 ( it took 6 mo s to handwire the ENIAC at U Penn with its CPU built of 10,000 Tubes and the Core memory built of teeny Magnetic rings ! ) proposed his simple SERIAL architecture of a single CPU tied to one block of memory fetching and processing just one set of Instruction & Data and then testing them for branching. .This is the only way the Parabolic Differential Equations needed to design an Implosion Bomb ( Nagasaki ) could be solved on time. People have been trying PARALLEL computing since the late ’60s ( ILLIAC ) but progress in predictive data and instruction fetches have not been that great. It is ONLY because we have made hardware so cheap and through Adv. Packaging even removed the so called Memory Wall between CPUs and DRAMs and Cache Memory that folks can do Multi Processors in spite of the low efficiency of Parallel Computing. So STOP BASHING old JvN unless you are ready to take a POP QUIZ on the von Neumann Boundary Conditions !
I always admired analog computers until got my first analog lesson. Besides my grades, it’s fact that in 40s they could process images to transfer and back as live tv. To that capability we could only reached 2000s in digital. Maybe another light will shine in the ai/ml world.
I bought gsi module, residing in my drawer. Saw before big promises and big fundings, but also small vanishes. Hope that in that field more tech emerge.
I am not sure I ever suggested that parallel computation was some how superior to a single processor. What I suggested is that a processor’s relationship to memory is what needs to change. Single large memory spaces are inefficient in time and energy and cache is often a poor solution for that – especially for tasks like AI when the access patterns are more predictable.
I would imagine the generalisation of the memory centric computation to be similar to a distributed system where processing units communicate by a small set of memory units and form a network. Hardware will constrain the number of processors and the connectivity limits, and software will specify how these processors share memory units and do computation.