Tradeoffs become more important as designs become more complex, more critical, and more long-lived.

Electronic systems comprise both hardware and software. Which functions are implemented with hardware and which with software are decisions made based upon a wide variety of considerations, including concerns about quality and reliability.
Hardware may intrinsically provide for higher device quality, but it is also the source of reliability concerns. This is in contrast with popular views of software, largely because software can be patched more easily.
“Quality and reliability are both considered critical in the design of hardware and software,” said Rob Aitkin, fellow and director of technology on the research team at Arm. “But they can mean different things in hardware than they do in software.”
There are fundamental reasons that can give hardware higher quality, while software has higher reliability. But there are also measures that can be taken to ensure high-quality software and mediate the effects of long-term hardware degradation.
Quality vs. reliability
The notions of quality and reliability are often confused with each other. Quality reflects the state of a product when manufactured. If a product is shipped with a fault, that’s a quality problem. Reliability, on the other hand, reflects changes in a product over time. What might have seemed like a high-quality product at the outset ultimately may fail later in life.
A classic formula describes this relationship, referred to as a “bathtub” curve because of the shape. It shows a higher failure rate at the outset, decreasing to a steady level for most of the life of the product, and then increasing again as the product’s end of life approaches.
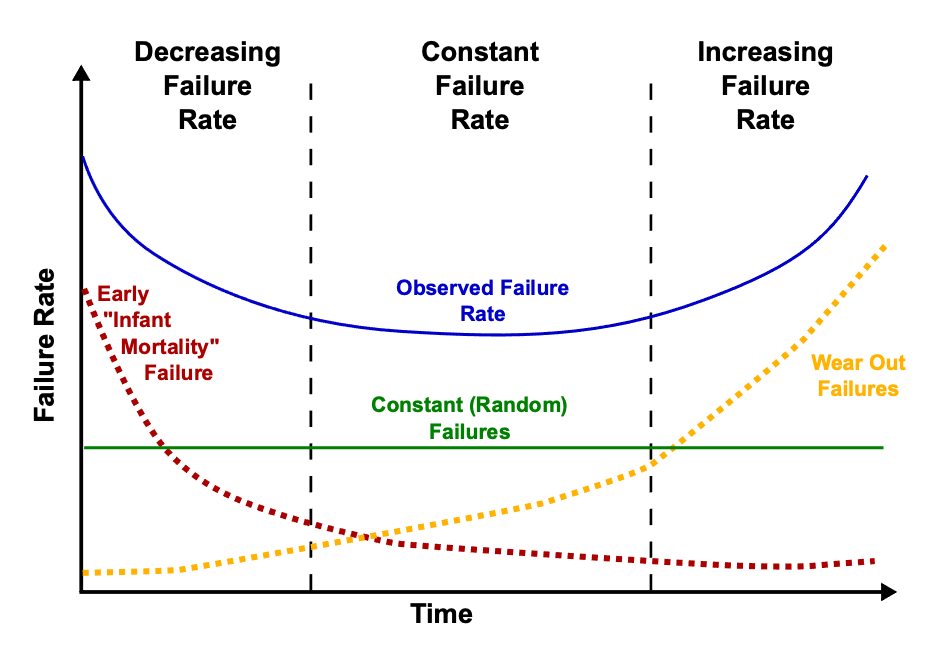
Fig. 1: The ‘bathtub curve’ hazard function (blue, upper solid line) is a combination of a decreasing hazard of early failure (red dotted line) and an increasing hazard of wear-out failure (yellow dotted line), plus some constant hazard of random failure (green, lower solid line). Source: Wikipedia
The “wear-out” failures are a classic representation of reliability. The “infant mortality” portion, however, takes a little more discussion. Early failures could represent a quality issue — something was wrong with the product when it left the factory, and whatever testing was done failed to catch it (or it was a test “escape”). It also could reflect a reliability issue if some element was intact after manufacturing but failed shortly thereafter. An example might be a poorly built contact, with enough of a connection to make it through test, but with the connection breaking after a nominal amount of use.
The key to the distinction is whether any early-device issue was there when the product left the manufacturing line. If so, it’s a quality issue. If the failure represents a change in the device after manufacturing, regardless of how soon the change happened, that’s a reliability issue.
Quality can reflect more than just an issue that occurred in manufacturing. If there is a bug in a device, regardless of whether it’s in hardware or software, that’s a quality issue because the device was shipped with it. The bug may not reveal itself until later in the use of the product — making it look like a possible reliability issue. But the bug didn’t arise over time. It was always there, but it was latent until conditions revealed it.
This line begins to blur, however, in complex systems and multi-chip packages, and it has broad business implications. Hardware and software may be within spec, but the overall system comprising multiple chips, embedded code, and various hardware and software processes push the overall system out of spec.
“With only one chip, you can tell if it’s good or bad, and I know when I pay that I’m buying the good chip or the bad chip,” said Alan Liao, director of product marketing at FormFactor. “When the packaging house takes one die from Company A and one die from Company B and integrates them together, if this whole package fails, who takes responsibility for a part that goes wrong? They need to get that data to work out that business model.”
In addition, chips are expected to last longer — particularly in applications such as industrial, automotive, robotics, 5G base stations, and even servers.
“There are ways to make virtual layers inside of chips with software, and to add things like redundant cores, but car companies in particular are trying to avoid replication of these relatively expensive chips,” said Jay Rathert, senior director of strategic collaborations at KLA. “That continues to drive quality. We’ve heard from a collaborative ecosystem of OEMs, Tier 1s and Tier 2 suppliers that they want to learn about these problems and try to avoid them. More than once we’ve heard lots of issues about increasing complexity, the need for cutting-edge chips, but also about problems with their maturity and how to address quality. Half of the failures today can be traced back to the fab.”
And finally, some random failures may or may not be truly random, but figuring out the answer requires both time and money.
“While the root cause of some field failures is truly ‘random’ and might only be caught by functional measurement of the active chip circuits themselves, there are significant reliability risks in today’s advanced technologies that are ‘systematic’ in nature,” said Dennis Ciplickas, vice president of advanced solutions at PDF Solutions. “This means that the physical-plus-electrical root cause of a circuit on a die that fails in the field also affects similarly-designed and/or nearby structures within the same die, neighboring die/zones on the same wafer, and wafers processed in the same lot, batch or timeframe within the fab. Capturing this systematic trend speeds both containment and root-cause diagnosis. This is why scribeline e-test data is commonly used as a wafer-level quality screen, even though product yield might look okay on those wafers. The use of ultra-high density resistor/transistor arrays and full-wafer, high-speed parallel parametric testing significantly increases the signal sensitivity of the scribeline measurement, and placing e-beam specific instrumentation, like our DFI (design for inspection) structures, inside the die vastly increases not only the signal sensitivity (to ppb levels) but also the spatial resolution.”
Software vs. hardware
The bathtub curve — and the attendant concept of reliability — fits nicely with hardware, because it’s well known that hardware ages over time. In addition, for the most part, hardware is susceptible to manufacturing mistakes (as opposed to design mistakes) to a far greater extent than software is, although a thorough test regime should make that a yield problem, not a quality problem.
This distinction is evident even in 8-bit MCUs that include configurable hardware blocks for pre-processing peripheral data. Those blocks sometimes are designed to remain awake while the processor sleeps because it saves power. If that functionality is handled in software, the processor would need to be awake to run the software.
“We’ve put small bits of configurable logic on our chips so that you can use those structures to apply little bits of logic without powering on the actual CPU,” said Wayne Freeman, product marketing, 8-bit MCU business unit at Microchip.
This is based on a general assumption, which is shared by many chip engineers, is that this configuration provides greater reliability due to greater likelihood of bugs in software. But software bugs make the issue one of quality rather than reliability. “If you can transfer a lot of the task handling into your peripheral hardware, you have to write less code,” said Freeman. “The less code you have to write, the fewer mistakes.”
The perception is that software has more bugs than hardware, making it a higher risk for quality issues. Replacing some of the software with dedicated hardware blocks, therefore, should provide higher quality. That’s because silicon chips are burdened with the need to invest in an extremely expensive mask set that will be used in production. Any bugs discovered after the masks are built mean that at least some — and perhaps all — of the masks will need to be replaced. That’s an expense no design team wants to be blamed for.
That drives an extraordinary level of verification prior to tape-out, which is the moment when the design is deemed complete and the design data is sent to the mask house for mask production. Between design verification, and what should be a solid test regime, the expectation is that chips will exit the fab with a very high level of quality. “The hardware design process is focused on creating a design that is as close to bug-free as possible when it is ‘taped out’,” said Aitkin.
Software, by contrast, isn’t usually perceived as having that same level of verification. “Hardware is tested way more than software,” said Neil Hand, director of marketing, design verification technology division at Mentor, a Siemens Business.
After all, if something goes wrong, the software can simply be patched — something that’s not possible with hardware. “Customers expect multiple iterations of software for the same hardware,” said Subodh Kulkarni, president and CEO of CyberOptics.
This is despite the fact that software can be tested in a far more natural setting than hardware. “In software design, alpha and beta testing are much closer to real deployment than their simulation or emulation-based hardware counterparts,” said Arm’s Aitkin.
In addition, updates can often, although not always, be managed with little cost. “The cost of a software update is not inherently expensive — although in some applications, it may be if you’ve got to ground a fleet of trucks or planes to do a software update.
The exception to hardware’s post-production immutability is programmable hardware, like an FPGA. The underlying device must be verified to ensure that a mask spin won’t be needed, but the final functionality will be determined by the hardware “program” created by the chip user. That program also may be highly verified, but there is no risk of a mask re-spin — and that aspect of the hardware also can be patched.
So at a surface level, it would seem evident that software, and programmable logic, have the potential for lower quality than full-on hardware. That would back up the claim that it’s better to use hardware for some functions, where possible.
On the flip side, software doesn’t age. The state of the software when shipped is how it will remain, theoretically, forever. Any changes reflect hardware issues — a failure in the memory where the code is stored or a developing problem with the processor that will execute the software. Reliability would appear to be exclusively a hardware issue. While replacing software with hardware blocks might lead the way to higher quality, there is a tradeoff. With hardware, aging and stress can take a toll over time. And the more complicated and finely tuned the hardware, the more things potentially can go wrong.
Improving software quality
Still, ensuring software quality for a program that will be executed on a variety of general-purpose computers is always difficult, given the variety of computer configurations. Testing all combinations is impossible, making it hard to be sure that testing efforts have been adequate.
Embedded applications are different. They reflect software programs intended for use on, at most, a very limited number of hardware platforms. Often that number is one. That can provide greater confidence in the thoroughness of the testing.
The complexity of many new systems-on-chip (SoCs) means they need emulators to test them. One of the strengths of an emulator is that it’s possible to run some amount of real software on the hardware image in the emulator. In theory, that could drive up the quality of the software at the same time as it wrings out the hardware.
But the purpose of running software in an emulator usually is to ensure that both the hardware and the hardware/software interactions work as expected. It may be only the drivers that are tested. “I’m picking what [software] I need to pick to test the hardware, more so than [testing whether] my software is bulletproof,” said Hand. Running full software programs may take longer than is feasible, because even though an emulator runs much faster than simulation, it’s still slower than the final system will be.
Agile development approaches also can create the impression that software might have lower quality, given the perceived focus on just getting something out there and then making changes if necessary. While that may be the case for low-impact software, it isn’t necessarily the case for mission-critical applications. “Even though we follow agile software development methodologies, there’s still a crazy amount of testing before we do a release,” said Hand. “Agile is a way to get to testing faster. I don’t think it eliminates testing.” In addition, agile methods are also used for hardware.
Even with an agile approach, nightly regression tests are standard for both hardware and software. “The biggest pressure we get from customers is making sure they can turn around their nightly regressions,” said Hand. The notion of “publishing” frequently in this context isn’t about an actual software release, but rather publishing to the top of the tree. That may happen many times for both hardware and software before the results are truly released for masks (in the case of hardware) or for user availability (in the case of software). The quality is not determined not by the use of agile or other approaches, but by the quality of pre-release testing.
Dealing with the reality of aging
The fact that aging affects hardware and not software isn’t a final verdict. A lot of effort goes into remedial steps that accommodate the reality of reliability issues and mitigate any effects they may cause. “Hardware is expected to last at least seven years for capital depreciation purposes,” said Kulkarni.
One approach that is growing in popularity is the use of in-chip monitors to keep track of critical device performance characteristics. This allows equipment operators to observe aging — and any other evolving misbehaviors — as they develop and before they become an issue. Referred to as preventive maintenance, it allows equipment to be replaced or repaired in an orderly fashion before a failure occurs. “The major value of our Agents lies in predictive maintenance,” said Noam Brousard, vice president, systems at proteanTecs, where “Agents” refers to the company’s implementation of monitors. “We can correlate trends with the physics of failure to anticipate problems before they happen.”
Hand concurred. “We want to get to [the point] where hardware is just as reliable as software, where you know it’s going to fail before it fails,” he said. “If you’re building a high-reliability system, it’s not just hardware. It’s not just software. We don’t just have to know how the hardware will fail. We need to make sure the software fails correctly, as well.”
The other environment where this is of particular concern is in safety-critical applications. Once limited mostly to military and aerospace applications, the automotive industry has brought functional safety into the mainstream. The idea here is that protective measures like redundancy be employed so that, if something does go wrong, the outcome is predictable and controlled rather than catastrophic.
“We can get to the necessary level of reliability, but it does require more than just developing high-quality parts,” said Steve Pateras, senior director of marketing for test products at Synopsys. “Active management is required, and right now there is very little active management in electronics.”
The reason is that reliability issues in many cases are a matter of physics. Active management works alongside those issues to reduce their impact. Software watchdogs can monitor hardware, and hardware watchdogs can monitor software. But in either case, nothing can be assumed to just work, and provisions need to be made for the occasion when they don’t work.
“Being able to predict reliability by having a baseline understanding of chips, and update those extrapolations with ongoing data to be able to maintain accurate predictions of where things are going, is the Holy Grail in all of this,” said Pateras. “We feel it has to be a hardware-based solution to ensure performance optimization, security optimization, reliability optimization, and performance and reliability prediction. If failure is imminent in a car, you want to take it off the road.”
Don’t worry about whether it’s hardware or software
Mentor discussed a way of approaching decisions of hardware or software by focusing holistically on an application, without creating a strong fork between hardware and software development. All of the requirements of the application must be verified and validated whether in hardware or software. “In that scenario, there really is no difference between hardware and software,” said Hand. “It is a function and you’re designing it together and you’re testing it together.”
Aitkin similarly pointed to a holistic view. “While software doesn’t have the same limitations in life span as hardware, software components exist as layers in a stack that includes both hardware and software, where the stack itself is designed to limit or accommodate the interlayer effects of reliability issues to the greatest extent possible,” he said.
In the abstract, given no extra effort, software can have lower quality than hardware, and hardware will have reliability issues that software won’t have. Adding more software does create the opportunity for more bugs. Adding more hardware does create more circuitry that can age and go awry.
In practice, however, it’s the extra effort that makes the difference. Software testing can be as rigorous as hardware testing. And hardware can be designed with measures that soften the impact of any reliability concerns. This can partly differentiate “good” products from “bad.” “Most high-performance, high-price system vendors tend to choose top-quality components and continue to iterate software,” said Kulkarni. “However, that’s not the case with lower-performance/lower-price vendors.”
John Hoffman, engineering manager at CyberOptics sees just one real difference between a hardware choice and a software choice. “The only fundamental tradeoff that applies to all systems between hardware and software is opportunities for future enhancements,” he said. There’s no one right answer, and decisions will likely be driven more by functional needs like cost and feature additions through future software upgrades. Any concerns about quality and reliability can be addressed through extra testing and design effort.
— Ed Sperling and Anne Meixner contributed to this report.
Related
Making Chips To Last Their Expected Lifetimes
Lifecycles can vary greatly for different markets, and by application within those markets.
Adaptive Test Gains Ground
Demand for improved quality at a reasonable cost is driving big changes in test processes.
Demand Grows For Reducing PCB Defects
Electrical test alone will not discover problems in increasingly complex and dense boards.
 |
 |
 |
 |
 |
 |
 |
Leave a Reply