Programmability shifts some of the burden from hardware engineers to software developers for ML applications.

FPGAs have long been used in the early stages of any new digital technology, given their utility for prototyping and rapid evolution. But with machine learning, FPGAs are showing benefits beyond those of more conventional solutions.
This opens up a hot new market for FPGAs, which traditionally have been hard to sustain in high-volume production due to pricing, and hard to use for battery-driven and other low-power applications. Their principal benefit remains flexibility, which is extraordinarily important for an industry as changeable as machine learning (ML). Not only do applications change in general, but networks and models can morph rapidly as continued training adds further refinements. and different vendors have different ways of addressing it.
“There’s a continuing battle between GPUs, FPGAs, and ASICs,” said Anoop Saha, market development manager at Mentor, a Siemens Business. “If the FPGA vendors didn’t supply [tools], then they’d have no chance.”
The first ML implementations have been software-oriented, leveraging CPUs and GPUs. Their challenge is extremely high energy consumption – even for a data center. “People are trying to innovate sooner with software, but it’s hard to handle the power,” said Patrick Dorsey, general manager and vice president of product marketing, FPGA and power products in Intel’s Programmable Solutions Group.
As a result, FPGAs provide a more attractive power solution than the software-programmable ones. “FPGAs are specifically better at doing high-performance, low-power applications due to parallelism,” said Shakeel Peera, associate vice president in Microchip’s FPGA business unit.
He’s not alone. “We’re seeing TOPS/W in an FPGA beat Nvidia, if you work at it,” said Intel’s Dorsey.
FPGAs also provide low latency and deterministic performance that can be hard to achieve with software-based solutions. “ASICs do about 5 TOPS/W, FPGAs 1 to 2 TOPS/W,” said Mike Fitton, senior director of strategy and planning for Achronix. In this case, as compared with software-based approaches, the performance doesn’t come at the expense of power.
Price still can be an issue for commodity applications, but few ML applications have reached that stage because models are evolving so quickly. “FPGAs aren’t good for commodities,” said Nick Ni, director of product marketing for AI and software at Xilinx. “Some of the stationary cameras, for example, have algorithms that are getting more mature.”
But that’s an uncommon situation at present. “In AI, we’re seeing [FPGAs] stay in production,” said Dorsey. That doesn’t mean cost is unimportant, however. Dorsey noted that, “Cost is huge. People look at it and say, ‘What’s my TCO [total cost of ownership]?’”
While flexible solutions dominate early in the evolution of a market, the usual follow-on would bring application-specific standard products (ASSPs) into the market to provide better performance, power, and/or cost efficiency. And many ASSPs are under development.
Still, these ASSPs have a tough balancing act, as well. They must bring computational efficiency while not taking on too rigid an architecture. Most of these efforts are targeting inference at the edge, and between today’s solutions and these newer chips, there’s likely to be a lot of fragmentation before the market settles on a set of preferred solutions.
Data centers, edge, and in between
FPGAs have found a home in the data center as acceleration vehicles for offloading CPU- and GPU-based inference engines. This has been particularly true for training, which always is performed in the data center, but they’re also used for inference.
At the opposite end of the spectrum, the edge is where most of the action is — particularly for automotive applications. These applications are more cost- and power-sensitive, but given the lack of ASSP solutions in production and the rapid changes in designs, FPGAs can compete well against processors. “FPGAs have an advantage at the edge. It’s very hard to go wrong with an FPGA when it comes to TOPS/W,” said Mentor’s Saha.
Meanwhile, an opportunity is growing in what Synopsys refers to as the “accumulation” market — devices like routers and switches lying on the network between the edge and the data center. This market always has been friendly to FPGAs, and in many cases the goal is to add ML capabilities to FPGAs that are already there. “There are lots of existing applications where they just want to add some intelligence to it,” said Intel’s Dorsey. “Thirty to forty percent of classic embedded business now involves some AI discussion.”
Added Achronix’s Fitton, “Pre- and post-processing is often already done in the FPGA,” allowing the inference design to share the same chip.
Design model challenge
Given the advantages that hardware-programmable solutions can provide over software-programmable ones, the obvious question becomes, “Why wouldn’t everyone simply use FPGAs?” And the answer boils down to one word: hardware. This is the Achilles’ heel for FPGAs.
According to U.S. Bureau of Labor Statistics, in May 2018 roughly 21.5 software engineers existed for every computer hardware engineer (with software engineers including both “applications” programmers and “system software” developers). Hardware developers work in lower-level hardware-design languages (HDLs) that are more about specifying hardware structures than they are about defining algorithmic functionality. It’s a very different mindset, and most engineers remain either in one camp or the other.
FPGAs, for the most part, require hardware design. If done at a low hardware level, that makes the number of engineers available for that work a rarer, more expensive breed. “You can’t afford a [hardware] engineer to do [the design],” said Mentor’s Saha. An ML strategy that relies on hardware designers must ensure a reliable supply of developers in order to have confidence in that strategy. Saha heard one customer say, “We know we’ll get an advantage in an FPGA, but it will take 8 to 10 months with 4 to 5 engineers.”
Still, most of the FPGA approaches include engines — either hard-coded or as IP — that are software-programmable. This gray area makes some FPGA solutions partly hardware and partly software. The Flex Logix approach takes this to an extreme, with all of the hardware design handled by Flex Logix, leaving the rest of the development process as a software exercise.
The particular challenge for ML is not just the hardware/software divide. It goes beyond that to the data scientist, who may be conversant in a high-level software language, but who isn’t purely a software developer. These designers remain particularly far from hardware design. As a critical constituent of any ML solution, it raises a significant challenge for FPGA vendors that must be able to sell to the data scientist through software tools that abstract the hardware away. “The software challenge is big,” said Intel’s Dorsey. As Peera noted, “In order to break out in the market, we had to get software engineers involved.”
Hardware structures critical to ML computation can be created by hardware engineers to the point where further model refinement can be done without hardware design. That might happen by simply instantiating IP, which could be managed by a higher-level tool. “Most engineers use their networks as is,” which means less hardware work, said Hussein Osman, market segment manager at Lattice Semiconductor.
There are two important considerations — the design flow and the design tools. Some FPGA companies separate out the design flows so that the hardware design can be decoupled to a large extent from the model design. That makes FPGAs more accessible to non-hardware engineers. But the second part deals with which tools are used and how changes to a model are implemented in the FPGA.
FPGA design details normally are specified in a low-level bitstream that is uploaded into the device. But when it comes to ML, some companies implement the entire model in the bitstream, while others use the bitstream only for the hardware portions, using a software binary file for the ML model specifics.

Fig. 1: Two simplified design models for ML applications on FPGAs. On the left, all aspects of the design are captured in a single bitstream. A data scientist may be able to design at a high level, but the tools pass those aspects of the design through the hardware compiler. On the right side, the high-level model data is captured in a separate binary file. The exact point at which changes to the model might require a hardware bitstream change will vary by FPGA vendor. Source: Bryon Moyer/Semiconductor Engineering
The design model has implications for ongoing design modifications and updates to devices already deployed in the field. Where the entire design is included in the bitstream, future changes will use the low-level FPGA hardware tools to create the updated bitstream even if high-level design tools avoid the need for any explicit hardware design.
In other cases, changes to the model result in changes only to a software binary, which usually will compile much more quickly than a full hardware recompile. In that case, the underlying hardware will remain constant while aspects of the model change. Exactly where the boundary is between software-only changes and hardware changes will vary by specific architecture.
One source of relief when it comes to hardware design is high-level synthesis (HLS), which can take algorithmic C and turn it into a hardware design. Because many algorithms start as software — and often C or C++ — porting this directly to hardware can be a big time-saver. While it still can require some hardware expertise to manage the process, it automates much of the design, saving time and effort. “What enables FPGA use is HLS and high-level tools,” said Saha.
One final challenge remains — debug. “Figuring out where things are going wrong is a big problem,” said Saha. If an issue arises with hardware that someone else built, the project can come to a halt while the appropriate experts are consulted.
Optimizing inference models
All of the FPGA toolchains operate at an abstract level, interfacing with the standard model-training frameworks in the cloud. At the top level, parameters (or weights) are created by the training process and laid into a known, popular model like ResNet, MobileNet, or YOLO. These parameters are simply numbers, and they could be stored in a data file.
The structure of the network itself is the next level. Pruning and fusing layers are optimizations on a trained network. In some engines, this can be done using software primitives. In others, this might result in a hardware change.
At the other end of the spectrum, expert ML developers may want to get in and either customize a network by hand or create an entirely new network. When working at this level, it’s almost guaranteed that a new hardware bitstream will be created, even if the hardware tools are buried within the ML toolchain.
For in-field updates, changing a bitstream means replacing the entire FPGA design with a new one. If an update affects only a binary file, then only that binary must be changed. The hardware bitstream can remain unchanged. This can be leveraged with even smaller granularity because a specific FPGA may be designed to support more than one model. “You could have multiple binaries for different modes,” said Joe Mallett, senior marketing manager at Synopsys.
If that includes hardware changes, partial reconfiguration can help. “One design model is to create a number of algorithms and use partial reconfiguration to swap them in and out,” said Dorsey.
This technique can be particularly powerful for data center-based accelerator boards that may be called on for different inference or training problems. Intel said that its reconfiguration takes about 100ms, although the company is working to get that down to tens of milliseconds. That allows for quick repurposing of an accelerator.
Multiple FPGA strategies
Just as startups are exploring a wide variety of ways of solving the ML problem, FPGA vendors also are taking a variety of approaches. One doesn’t even look like an FPGA from the outside. Many FPGAs provide both hardware and software programmability due to processor cores that can be created out of the fabric or instantiated as hard macros in the FPGA. These options make for different FPGA strategies.
The two biggest purveyors of FPGA — Xilinx and Intel — have very different strategies, as Achronix’s Fitton pointed out.
Intel is leveraging a broader product offering, with FPGAs as only one way to address they the market. It also has Xeon processors, which can be used in a brute-force manner in data centers, and a neuromorphic research project underway that may add to the company’s range of solutions. Intel’s FPGAs primarily leverage traditional FPGA resources. To date, the company has no hard blocks dedicated to ML processing.

Fig. 2: Intel’s latest FPGA family, Agilex. Source: Intel
Memory access is an ongoing challenge for ML, and that affects FPGAs as much as any other solution. One of Intel’s tactics is to leverage HBM memory. “We’ve added a lot of HBM to a lot of our FPGAs. Having that so close to the fabric helps with RNNs [recurrent neural networks] and speech,” said Intel’s Dorsey. At present, that means a 2D integration of HBM right next to the FPGA, interconnected by Intel’s EMIB connectors on the substrate.
Xilinx has gone in a different direction, adding an ML engine to the fabric of its Versal family. That hardened block gives Xilinx better efficiency at the expense of the flexibility of the fabric. The engine is driven by software, removing some of the hardware design concern.

Fig. 3: Xilinx’s Versal family. Source: Xilinx
Achronix is taking the homogeneous approach, although it has tweaked its DSP blocks to be better resourced for ML work. Their older DSP blocks were optimized for more traditional signal processing, such as filters, and therefore focused on 18-bit data. ML tends to work with smaller data units — especially at the edge — so the newer DSP is optimized for eight-bit integers. Note that Achronix supplies both packaged FPGAs and an embedded FPGA fabric as IP for integration into a system-on-chip (SoC).

Fig. 4: Achronix’s Speedster FPGA. Source: Achronix
Lattice always has targeted the low-cost, low-power market, and that hasn’t changed with its focus on ML applications. There are small functions — like wake-word recognition — that can be added to edge devices to start the ML processing. From there, the result can be handed off to the data center for the bulk of the heavy processing. “[The inference we do] is mostly detection, but key phrases and hand gestures are recognized,” said Osman.

Fig. 5: Lattice’s sensAI offering. Source: Lattice
Meanwhile, Microchip is touting its new VectorBlox tools for its PolarFire FPGAs. Their strategy removes hardware design as a requirement for ML on an FPGA. Microchip has IP to instantiate an engine on the FPGA, and the rest of the model information is treated as software and turned into a binary file —a large one often referred to as a “BLOB” (for “binary large object”).
With this BLOB, Microchip can manage multiple models at the same time. While pure concurrency is possible by instantiating more than one engine, a single engine can also handle multiple models either sequentially or quasi-concurrently.
The engine pulls the model information from the BLOB in memory. If there are multiple binaries, a pointer indicates which BLOB to use at a given time. That BLOB isn’t loaded as a whole. The pieces of the model are referenced as used. “Switching the BLOB is like changing a pointer location. When the MXP runs, it is pulling the layer information from the BLOB each time. It is practically zero time to move between multiple neural networks,” said Jamie Freed, senior architect for the FPGA Business Unit at Microchip.
The quasi-concurrency is handled through time-slicing. If a video is being processed by more than one model at a time, each model runs a full frame, one after the other. Once all models have processed that frame, the cycle starts again with the next frame.

Fig. 6: Microchip’s VectorBlox neural-network engine. The CNN IP handles all of the convolution; the MXP handles pre- and post-processing as well as activation and pooling; and the Mi-V (their SiFive implementation) core can handle control and other software. Source: Microchip
Flex Logix hides its FPGA nature. While it leverages a programmable fabric internally, it fixes that configuration in its products, meaning that customers can’t use them as FPGAs. Flex Logix literally straddles the line between a programmable FPGA solution and a device with behaviors dedicated to ML. “It’s a hybrid ASIC/FPGA,” said Flex Logix CEO Geoff Tate. “The user programs the neural network model. They do not program anything lower level, including the eFPGA, just like an Intel customer isn’t writing microcode or caching algorithms.”
The company’s block diagram shows an eFPGA on the chip, but it’s used only by the higher-level tools in the service of the model being implemented. The designer has no independent access to that eFPGA block.

Fig. 7: Flex Logix’s InferX block. The eFPGA is not available for general-purpose use. Source: Flex Logix
Finally, there’s a newcomer in the FPGA world — Efinix. While the company has targeted performance and power to edge applications, at present it’s a standard FPGA story. Efinix has no declared dedicated ML message, although Sammy Cheung, founder, president and CEO, noted that the “pipeline and wide-bus management are well suited to ML.”
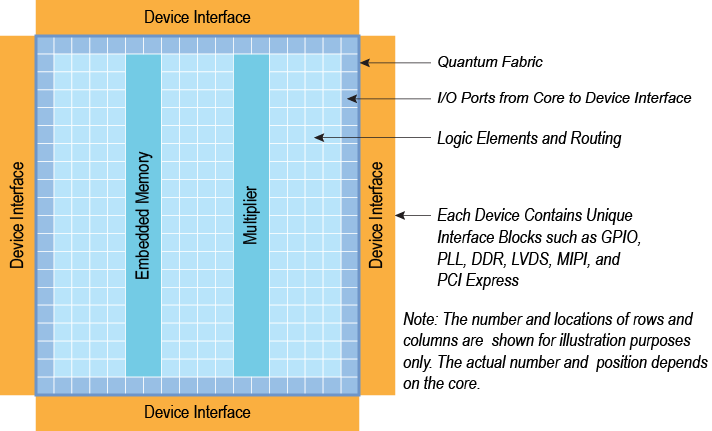
Fig. 8. Efinix’s Trion architecture. Source: Efinix
Summarizing the approaches that different vendors take:
While FPGA success in high-volume applications appears likely as those applications materialize in the next few years, they will be tested by the new round of ASSPs being readied for market. “New ASSPs are focused on specific configurations,” said Xilinx’s Ni. “By the time it comes out, the industry will have moved on. Everything is happening so fast.”
Regardless of whether those ASSPs get traction, FPGAs clearly will have a role in development and lower volumes regardless, so they will remain a part of the ML landscape for the foreseeable future.
Related Articles
FPGA and eFPGA Knowledge Center
Top stories, videos, special reports, blog and whitepapers about FPGAs and eFPGAs.
Using FPGAs For AI
How good are standard FPGAs for AI purposes, and how different will dedicated FPGA-based devices be from them?
FPGA Design Tradeoffs Getting Tougher
As chips grow in size, optimizing performance and power requires a bunch of new options and methodology changes.
The Challenges Of Building Inferencing Chips
As the field of AI continues to advance, different approaches to inferencing are being developed. Not all of them will work.
 |
 |
 |
|
 |
|
 |
Leave a Reply